Below are some thoughts on how I use Git and SourceTree.
First some terminology
- Repository:
- A database containing a bunch of objects of the following kinds
- commits,
- blobs (each of which represents the contents of a file at some time),
- tree objects, and
- annotated tags.
- branches (also described),
- an index (described below
- information about how to contact other repositories.
- Blob
- A blob is just the contents of an ordinary file at some point in time. In some cases the data is compressed in the database.; that's really not something you need to concern yourself with. Blobs are immutable, so once created they always have the same contents. The interesting thing is how blobs are addressed. Each blob is given an address that is a hash of its contents. Since Git uses a cyptographically secure hash function with 256 bits of output, the chances pretty good that any two blobs that have the same address. represent files with exactly the same content.
- Tree
- Just as a blob represents a snapshot of the contents of an ordinary file, a tree object represents a snapshot of the contents of a directory (aka folder). Tree objects are immutable. A tree object can be thought of as a sequence of tuples, each of the form (t, p, n, a) where t gives the type of object (blob, tree, etc), p is a number representing file permissions, n is a file name, and a is the address of the file (i.e., its hash code). Trees objects are also addressed by secure hash codes.
- Commit:
- A commit object consists of
- the address of a tree object (this represents the value of the commit's file tree).
- the addresses of this commit's parents (these parents are themselves commits),
- a message,
- a time stamp,
- the names of the author and the committer.
- Branch:
- A variable whose value is the address of a commit. Branches are mutable and are local to repositories; for example there might be a branch called master in my local repository and a branch called master in the hub repository; they are not the same and might, at some points in time, have different values. Each repository has two sets of branches: Local branches are intended for local work. Remote tracking branches represent local branches of other (remote) repositories; however the value of a remote tracking branch could be out of date with respect to the branch that it is tracking.
- Currently checked out branch:
- The branch that was most recently checked out. Making a new commit typically updates this branch.
- Working copy:
- A state of the file tree represented in a computer's file system. Each time you check out a branch, the working copy gets overwritten.
- Index (also called the Staging Area).
- A place in a repository where Git keeps changes that will become part of a commit in the future. You can think of the Index as a sort of mutable commit. The commit action takes all the changes in the index, makes a proper commit out of them, and clears the index.
- Merge:
- A merge operation combines two commits to create another commit. If we merge two commits x and y that have a least common ancestor z, then the result commit w=merge(x,y) will contain all changes from z to x and also all the changes from z to y. Here is an example where we consider a file tree that contains only one file, so the state of the file tree is simply a sequence of characters. Suppose z is a⏎b⏎c⏎d⏎e⏎f⏎ [The ⏎ represents the end of a line.] and x is a⏎c⏎d⏎e⏎f⏎ and y is a⏎b⏎c⏎d⏎e⏎f⏎g⏎. The changes from z to x is {delete the b between a and c}. The changes from y to z are {add a g after the f}. The union of the changes is {delete the b between a and c, add a g after the f}. So w is ac⏎d⏎e⏎f⏎g⏎. Sometimes it's not clear how to merge files, and in that case there is a "merge conflict". When y is the least common ancestor of x and y, then there is no need to create a new commit, so merge(x,y)=merge(y,x)=x. This is called merge by fast-forward.
- Line of development:
- A sequence of commits that may get added to over time. "Line of development" isn't really a Git concept, but I find it useful to think about lines of development. Often people use the term "branch" for this, but that's confusing because in Git a branch is a variable whose value is the address of a single commit; not a sequence of addresses of commits. Also, while each Git branch is associated with one repository, a line of development spans multiple repositories. I found Git much easier to use once I finally realized that branches and lines of development are different (but closely related) concepts. So next I'll try to explain with an example what I mean by a line of development.
- There is GitHub's x branch, i.e. a copy of the branch that is on the hub. [I'm assuming here that the central repository is GitHub, but it could just as well by Git Lab or Bit Bucket or a private server.]
- There is a tracking branch in your repository; this is called origin/x.
- And there is your local copy of the branch, which is called x.
- GitHub's shared,
- my origin/shared,
- my shared,
- my feature,
- GitHub's feature.
More on "lines of development"
Consider this evolution of a system, In the pictures commits are ordered in the order they are created (from left to right)

The five branches
Usually you only have to worry about two lines of development at a time: a shared line (typically called master) and a line that only you are working on. For illustration I'll call the shared line "shared" and the other line "feature". In implementation the lines of development are represented (sort of) by branches. But thanks to Git being distributed, line of development x is represented by actual branches in a number of places:my shared ≤ my origin/shared ≤ GitHub's sharedand
GitHub's feature ≤ my featureIt's also a good idea to try to fold any changes made to the shared into our feature as soon as they show on GitHub's shared branch. So we try to keep
my shared = my origin/shared = GitHub's shared ≤ my featuretrue as much as practical. (I.e., that my feature is descended from my shared, which is the same as the tracking branch which is up to date.) We do this with catch-up merges. This way, when we read, edit, and test our code, we are reading, editing, and testing it in the context of all completed features. Furthermore, when a pull-request is merged we want
my shared = my origin/shared = GitHub's shared ≤ GitHub's feature = my featureThat way merge-conflicts won't happen on GitHub's server.
Information flow
The flow of information that I use is shown in the figure. I'll explain each part below.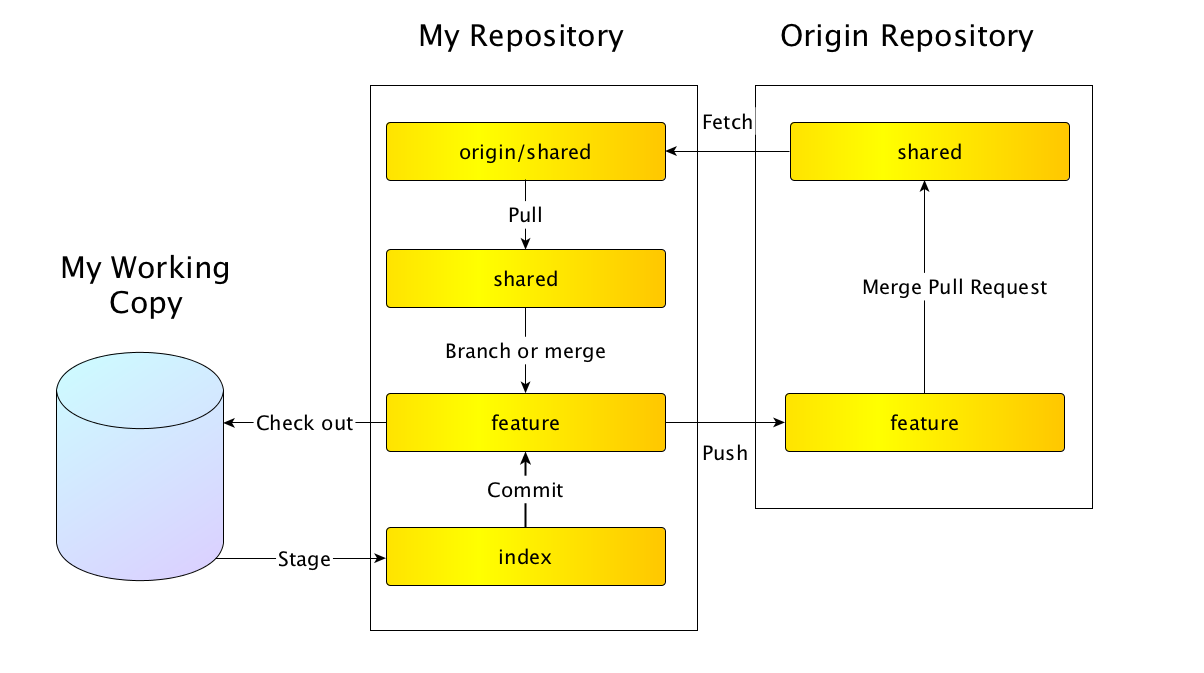
Basic operations
For the rest of the article I'll assume you are using SourceTree. Of course everything SourceTree does can also be done from the command line. Some of the basic operations of SourceTree work like this (somewhat simplified):- "Fetch" updates all your tracking branches. So Fetch means my origin/x := GitHub's x, for every x branch in GitHub's repository. Typically we use Fetch to bring changes made to GitHub's shared to my origin/shared.
- "Pull" means update my current branch from GitHub's repository. So Pull means my origin/x := GitHub's x ; my x := merge( my x, my origin/x), where x is the currently checked-out branch. Typically this is a fast-forward merge. (Usually I do a Fetch first and then a Pull if x is behind origin/x. When x is behind origin/x the merge is done by "fast forward", i.e., we have my x := my origin/x). Typically we use Pull to bring changes made to GitHub's shared to my shared.
- "Branch" means create a new branch. It means y := x where y is a new branch and x is the currently checked-out branch. Typically we use Branch when we start working on a new feature.
- "Merge" means my x := merge(my x, my y) where x is the currently checked-out branch and y is another branch. Usually we either merge my shared into my feature or the other way around. In the flow I use, merges are always merging my shared with my feature to make a new value for my feature branch.
- "Check out" updates the working copy to the value of a particular commit. When you check out a branch it updates the working copy to be the same as the branch's value and it makes that branch the current branch. In the flow this is used to check out my feature branch. Some operation in SourceTree only apply to the currently checked out branch, so there are times you will check out a branch just so you can do something else with it, such as a pull.
- "Stage" Staging means moving changes that are in the working copy to the index.
- "Make and merge a pull request (or merge request)". A pull request is a request for someone else to review the changes on a branch and to merge one branch into another. (Pull requests are called merge requests on Git Lab, which is a better name in my opinion.) Pull requests are not a feature of Git, but rather of hosting services such as GitHub. SourceTree can help you create merge requests. The actual merging of the pull request is done using GitHub's web interface.
- In source tree click on Fetch
- If shared and origin/shared are the same, stop
- Check out the shared branch by double clicking on "shared" under "Branches" on the left sidebar.
Click on Pull to get the local shared branch up to date with origin/shared - Catch up the shared branch (see above)
- Check out shared (if not already there).
- Click on Branch.
- Type "feature" as the New Branch. Click ok.
- Check out feature (if not already the checked out branch).
- Make changes to the files. Run tests. Etc.
- Back in source tree, Cmd-R (Mac) or Cntl-R (Windows) or View >> Refresh
- Select "Uncommitted changes"
- Review all unstaged changes.
- Stage all changes you want as part of the commit.
- Click Commit. (This doesn't actually do the commit.)
- Enter commit message
- Click on "Commit" button at lower right. (This does the commit.)
- Push the new commit to the origin, by clicking Push and OK.
- If you've never pushed the branch before you may need to check a box in the previous step before clicking OK.
- Catch up the shared branch (see above).
- If shared is an ancestor of feature you are caught up. Stop.
- Check out feature (if not already the checked out branch).
- Click on merge.
- Select shared.
- Click OK.
- Check for any merge conflicts. If there are merge conflicts they need to be resolved. That's a whole other story. (Maybe another blog post.)
- Even absent merge conflicts, there may be silent problems that prevent compilation or introduce bugs. So carefully inspect all differences between the merged version and the previous version of feature. Also recompile and run unit tests.
- Click on Push.
- Catch up the feature branch. (See above.) Be sure to push the feature branch to the server.
- If there are any problems, such as merge conflicts or failed tests, make sure they are all resolved before going on.
- On GitHub, make a new "Pull Request", being careful that it is a request to pull feature into shared.
- At this point, you might want to request someone else to review the pull request.
- Wait for comments or for someone else to merge the pull request.
- Or if no one else merges the pull request, merge it your self.
Recipes for common tasks
Here are some recipes for doing some common tasks with SourceTree.Catch up the shared branch


Make a feature branch


Make your own changes


Catch up the feature branch.
(Do this fairly frequently)

Merge your feature back to the shared branch.
(Do this when you think it's complete and ready for review.)


Merging
There are three ways to merge. Say we are merging commit x and commit y. There is usually a unique most recent ancestor, call it w. You can think of x-w are being the set of changes that would chance w's tree into x's tree. Similarly y-w is the set of changes that would change w's tree into y's tree. I'll use w + C to mean the tree you get by applying a set of changes C to the tree of w, so in particular w + (x-w) = x, for all x and w. (I'm being very sloppy here at distinguishing between commits and their associated trees; really I should say w.tree + (x.tree -w.tree) = x.tree; I hope this isn't too confusing.)
* An ordinary commit makes a new commit, z, whose tree is equal to w + ((x-w) & (y-w)). Where & is some way of combining the two sets of changes. When there are merge conflicts, the & operator isn't clearly defined and the developer needs to help git decide how to combine the two sets of changes. The parents of the new commit are x and y.
* A fast forward merge. When y is the the least common ancestor of x and y (i.e. y=w), the set of changes (y-w) is the empty set, which means that w + ((x-w) & (y-w)) = w + ((x-w) & ∅) = w + (x-w) = x. So if we do a regular merge we would get a new commit z that has the same tree as x. So the only difference between z and x will be the parentage, date stamp, message, and possibly author. In this case there is the option of not creating a new commit and simply saying that the result of the merge is x.
* Rebasing merge. The idea of rebasing is to find a set of changes that can be applied to x to get the same tree that we would with a regular merge. In the simplest case, suppose that y's parent is w. Let C = ((x-w) & (y-w). Then we can make a new set of changes C' so that w+C = x+C', now we can make a new commit z whose parent is x and whose tree is x+C'. This is really just the same a an ordinary commit except that we don't make y a parent of the new commit. In general, rebasing works on commit at a time, so if the sequence of commits from w to y is w, y1, y2, y3, y, then 4 new commits are created and chained in front of x. Let's call these x1, x2, x3, z. The tree of x1 is x + (y1-w)&(x-w) and its parent is x. The tree of x2 is x1+(y2-y1) and its parent is x1. The tree of x3 is x2+(y3-y2) and its parent is x2. The tree of z is x3 + (y1-y3) and its parent is x3. At least this is what I think happens. z is the result of the merge. At this point, y1, y2, y3, and y are typically discarded. Essentially what we are doing is saying what would the world be like if I didn't startworking on y1, y2, y3, and y, until after x was done. I.e., what sequnce of commits would I have made on top of x to get the same effect as merging x and y.
Some people seem to like rebasing. I don't because:
- It creates version of the software that are never tested. In our example x1, x2, and x3.
- It creates a timeline that doesn't reflect reality. For one thing thing the dates on x1, x2, and x3 will not be the same as those on y1, y2, and y3.
- It is complicated to roll back. Suppose we later decide that the changes from w to x were a mistake. We can't simply go back to y since commit y is now lost.
- It complicates life in other repositories.
Fast forward merge is fine in most cases. But as mentioned above, I like to have at least one ordinary merge at the end of each line of development.